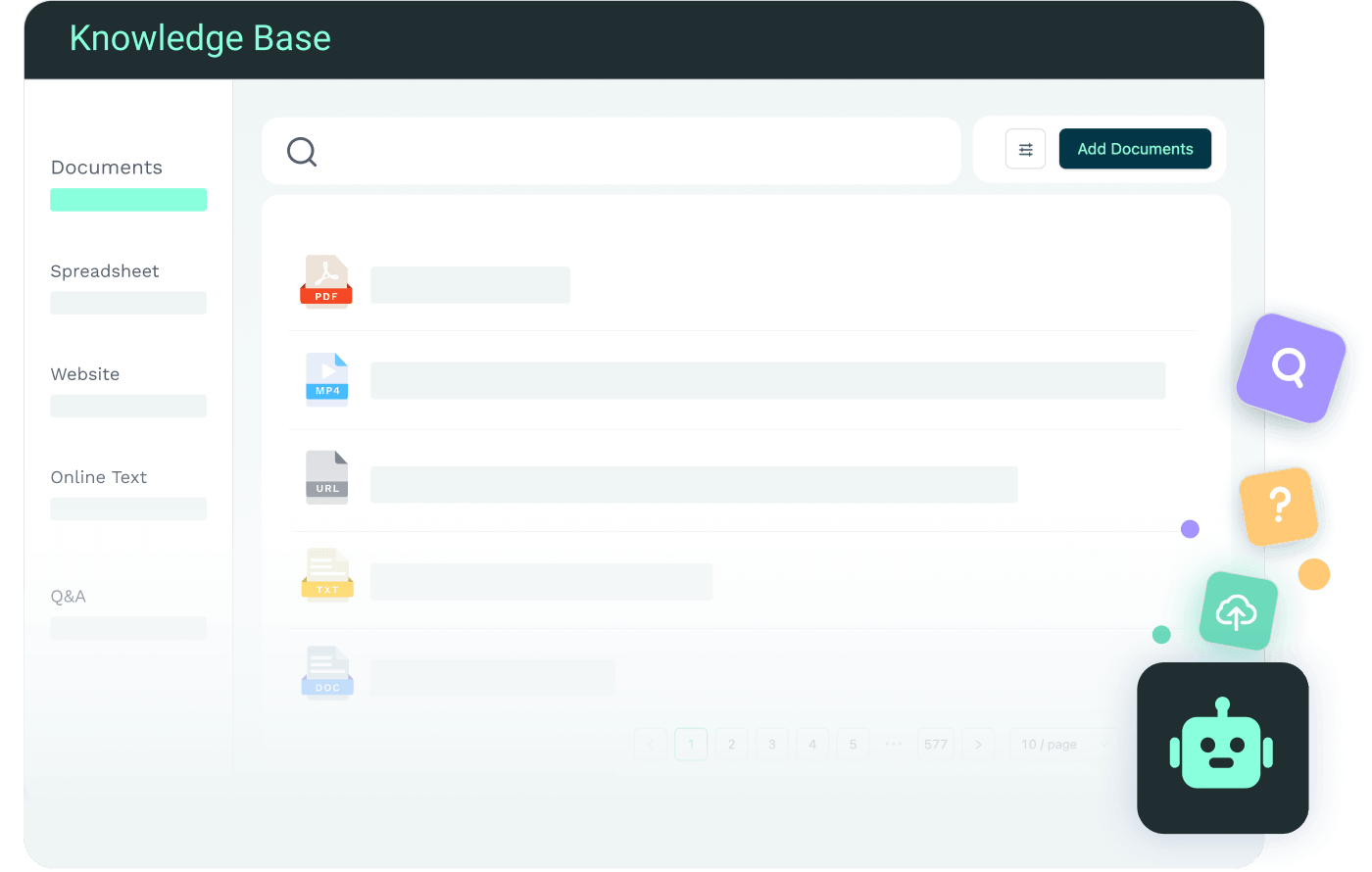
What Is Possible with the Knowledge Base Feature
Build a Systematic Enterprise Knowledge Base
Support both unstructured and structured knowledge, including documents, tables, and more, to freely build an exclusive knowledge base.

Precisely Extract Key Data from Unstructured Documents
Preserve the complete structure of PDFs and other documents, expertly parse complex documents such as financial reports, perfectly meeting enterprise needs.

Ensure Maximum Precision for Complex Queries
Support semantic and keyword searches, multi-channel recall, and re-ranking to ensure more precise knowledge recall, significantly enhancing the quality of LLM responses.
Provide Instant and Accurate Answers with References
Display various citation methods to help users verify content authenticity and boost trust.
How does the Knowledge Base works
Import your data
Debug and test
Fine Tune
Manage Knowledge base
- Convert unstructured data (doc, pdf, md, txt) into structured markdown format.
- Supports complete storage in formats such as csv, xls, and xlsx.
- Input text-based Q&A or provide direct input Q&A.
- Import data from third-party platforms like Google Drive, Web, or via API integration.
Choose GPTBots for More Features
Streamlined Knowledge Management
Manage knowledge with ease through online editing and real-time updates, supporting synchronization across multiple channels for greater efficiency.
Advanced Document Parsing
Efficiently parse data from PDFs, digital documents, and images with precision and speed.
Enhance Responses with Cutting-Edge Models
Utilize the latest embedding and rerank models to significantly improve the retrieval and recall capabilities of your knowledge base.
100% Data Security
Advanced encryption and data isolation techniques secure data, meeting several certification standards.
GPTBots Built-in Knowledge Base Use Case
GPTBots’ AI Agent transformed how a healthcare provider interacted with patients. By integrating medical records, treatment protocols, and other structured and unstructured data, they created a robust and exclusive knowledge repository. The exclusive knowledge base ensured more precise answers, delivering authoritative, detailed, and swift solutions to patients’ needs.
Within just a few weeks, their AI Agents began efficiently handling complex patient queries, providing accurate and reliable responses. The average response time was reduced by 50%, and patient follow-up questions decreased by 35%. Overall, patient satisfaction improved significantly.